










IBC2022 Tech Papers: Automatic commentary training text-to-speech system for broadcasting
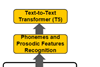
IBC2022: This Technical Paper introduces a method that automatically extracts speech from broadcast commentary through combination of deep learning methods and automatically generates training data for TSS by using the latest speech-recognition method.
Abstract
Thanks to the rapid progress in deep learning technology, the text-to-speech (TTS) system we developed has achieved the same quality as human speech, enabling us to launch a fully automatic program production system known as “AI Anchor.” The TTS system needs a large amount of speech and label data, but data production costs are high and TTS speakers cannot be easily added. This paper presents a novel TTS method featuring automatic training from broadcast commentary. It uses an approach that allows for a new semi-supervised learning method using an accentual data recognition method specialised for TTS.
We have automated the entire training process for generating training data and performing label data recognition from broadcast commentary. In this paper, we present practical examples of automated program production such as an automatic weather forecast system for radio, automatic sports commentary system, and slow and easy-to-understand commentary news using our automated TTS training system based on broadcast commentary.
Introduction
Owing to recent progress in deep learning technology, text-to-speech (TTS) technology has come to be widely used in smartphones, smart speakers, social networking service (SNS) videos, etc. We have been researching and developing this technology and have been putting it to practical use in broadcast programs and video distribution such as “AI News Anchor” since 2018. However, TTS requires studio-quality speech training data, but this increases costs. The work of generating training data requires anchors, sound engineers, directors, and studio resources as well as annotation of the phoneme label files, which is the most costly. However, given that a broadcast station airs high-quality speech on a daily basis, studio-quality speech is easy to acquire. With this in mind, we developed a technique that treats broadcast commentary as training data for TTS.
The work presented here focuses on semi-supervised learning (SSL) TTS, which uses state-of-the-art speech recognition and broadcasting commentary data. In related research, the system of Chung considered single-speaker and unpaired noisy data for SSL TTS, but the system did not use speech recognition, multi-speaker learning, and sequential audio stream like broadcasting commentary. Thus, this method could not be used for broadcasting commentary. In addition, the system of Tu considered multi-speaker learning and speaker identification for SSL TTS, but it did not train sequential audio streams like broadcasting commentary, its architecture was outdated, and its evaluation results were worse than those of the latest TTS. The proposed method automatically generates data from audio streams like broadcasting and adopts a state-of-the-art TTS model. Also, many TTS methods do not support sequential audio stream and only support waveforms one sentence long. Moreover, the proposed method is versatile for many of the latest TTS methods.
In this paper, we introduce a method that automatically extracts speech from broadcast commentary through a combination of deep learning methods and automatically generates training data for TTS by using the latest speech-recognition method. We also introduce practical examples of applying TTS for broadcasting.
Read the full article
Sign up to IBC365 for free
Sign up for FREE access to the latest industry trends, videos, thought leadership articles, executive interviews, behind the scenes exclusives and more!
Already have a login? SIGN IN
IBC is owned by
IBC is run by the industry, for the industry. Six leading international bodies own IBC, representing both exhibitors and visitors. Their insights ensure that the annual convention is always relevant, comprehensive and timely. It is with their support that IBC remains the leading international forum for everyone involved in content creation, management and delivery.






Site powered by Webvision Cloud